축에 평행한 장애물 피하기 (With Sensor)
이전 Enviroment 와는 다르게 벽을 세워 떨어지지는 않으나, 타깃의 생성 위치를 전체 Area 로 넓혔다.
또한 이번에는 RayPerceptionSensor 를 이용할 것이다. Roller 는 바라보는 방향이 없기 때문에 센서 각도를 180 으로 설정했다.
Observation (First Try, Second Try)
| sensor.AddObservation |
|---|
| rigidbody.velocity.x |
| rigidbody.velocity.z |
위 2개의 값과 센서에서 받은 정보를 바탕으로 간단한 장애물을 피하는 학습을 진행하였다.
rigidbody 의 velocity 를 준 이유는 Agent 의 현재 속도를 알아야 더 정확한 Action 을 취할 수 있기 때문이다.
First Try
Policy
| Situation | Reward | EndEpisode |
|---|
| 장애물에 닿아있는 동안 | 틱당 (-30 / MaxStep) | |
| 타깃에 도달 | +5 | O |
| Living | 틱당 (-2 / MaxStep) | |
이전까지는 틱당 Reward 를 줄 때 -0.001, -0.002 와 같은 고정된 수치를 이용했으나,
그렇게 되면 에피소드 길이가 길어질 경우 그 총량이 커지고, 짧아질 경우 총량이 작아지는 문제가 생긴다.
그래서 이번부터는 MaxStep 으로 나눈 값을 이용하여 에피소드 길이에 상관없이 동일한 총량을 가지도록 하였다.
Hyperparameter
접기/펼치기
behaviors:
RollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 1000000
time_horizon: 64
summary_freq: 10000
Result
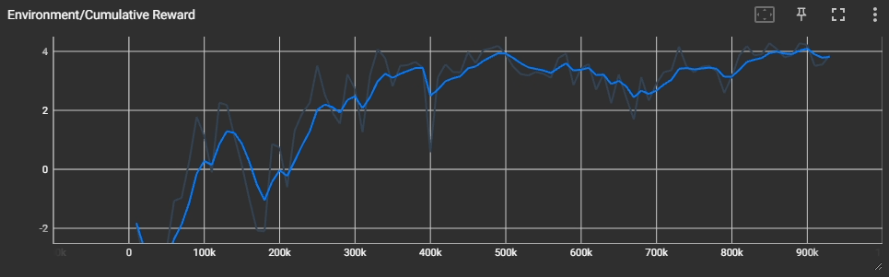
학습이 되긴 되었는데... 일단 Reward 가 특정 값에 수렴하지 않았고, 위에서 보는 것처럼 약간 돌아가는 느낌이 있었다.
그래서 Hyperparameter 를 조금 바꾸어 학습을 다시 진행해 보았다.
Second Try
Policy
| Situation | Reward | EndEpisode |
|---|
| 장애물에 닿아있는 동안 | 틱당 (-30 / MaxStep) | |
| 타깃에 도달 | +5 | O |
| Living | 틱당 (-2 / MaxStep) | |
First Try 와 동일
Hyperparameter
접기/펼치기
behaviors:
RollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 512
buffer_size: 2048
learning_rate: 3.0e-4
beta: 1e-3
epsilon: 0.15
lambd: 0.95
num_epoch: 4
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 1000000
time_horizon: 256
summary_freq: 10000
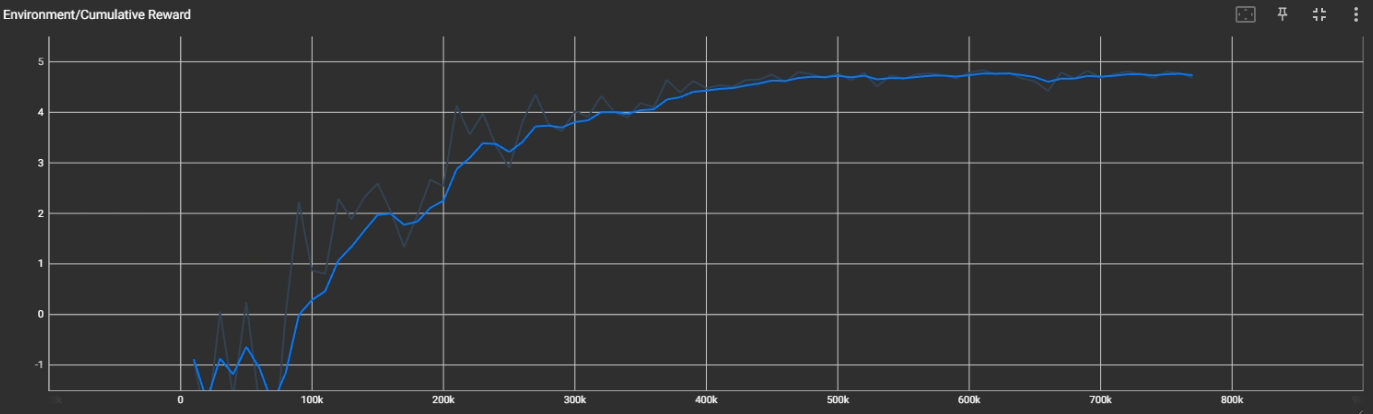
조금씩 변경하긴 했으나, batch_size 와 buffer_size 값을 크게 증가시켰다.
Result
벽에 부딪히면서 가긴 하지만, 그래도 확실히 전보다 좋아진 것을 확인할 수 있고, Reward 도 거의 5에 수렴하는 것을 볼 수 있다.